
Georgetown University Multilayer corpus (GUM)
- English
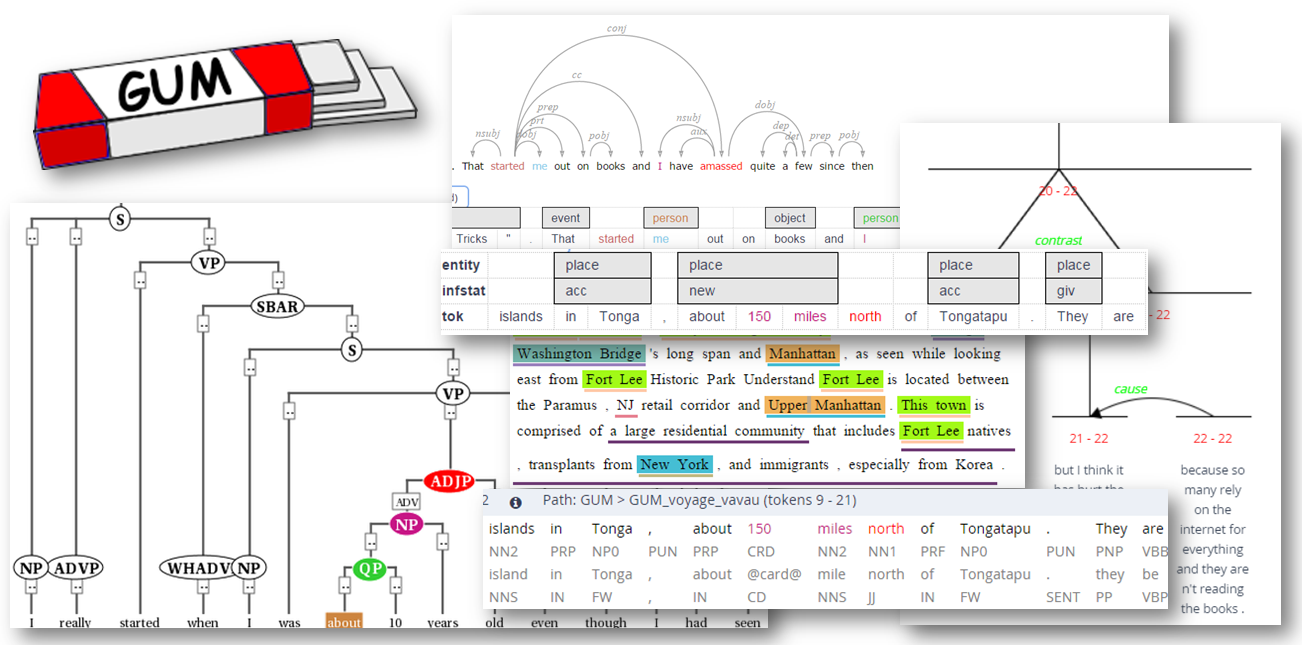
Description
Taken from the corpus website:
GUM is an open source multilayer corpus of richly annotated texts from twelve text types. Annotations include:
- Multiple POS tags, morphological features and lemmatization
- Sentence segmentation and rough speech act
- Document structure in TEI XML (paragraphs, headings, figures, etc.)
- Normalized ISO date/time annotations
- Speaker and addressee information (where relevant)
- Constituent and (enhanced) Universal Dependencies syntax
- Information status (given, accessible, new, split antecedent)
- Entity and coreference annotation, including bridging anaphora
- Entity linking (Wikification)
- Discourse parses in Rhetorical Structure Theory and discourse dependencies
The corpus is collected and expanded by students as part of the curriculum in LING-367 Computational Corpus Linguistics at Georgetown University. Each year students begin by choosing a text from within one of four possible genres, and as we learn about different annotation types and standards, participants are responsible for analyzing their own document, to which they add more and more layers of analysis: from part-of-speech tagging, through treebanking, entity recognition, discourse parsing, and more. Texts are chosen from openly available sources, and students who wish to contribute their analyses at the end of semester can do so under a Creative Commons license. The resulting data is checked for consistency and published online via GitHub. See this page for a list of contributors.
Specific task guidelines:
- Tokenization and sentence splitting
- Tagging and lemmatization
- Universal Dependencies
- Entities, anaphora resolution and information structure
- RST discourse parsing
Domains and Genres
- academic
- bio
- conversation
- fiction
- how-to
- interview
- news
- speech
- textbook
- travel
- vlog
References
Zeldes, Amir (2017) The GUM Corpus: Creating Multilayer Resources in the Classroom. Language Resources and Evaluation 51(3), 581-612.